
Uno de los primeros soportes usados en los ordenadores para grabar datos fue el cartón o papel. Tarjetas perforadas o cinta de papel perforada se utilizaron para introducir datos en los ordenadores o guardar información. En la actualidad sistemas como los códigos de barras o códigos QR se utilizan para grabar en papel códigos o direcciones de Internet. Después de desarrollar el sistema para grabar archivos en casetes me decidí a crear un sistema similar para grabar un archivo en una hoja de papel y después escanearla para recuperar el archivo a partir de la imagen.
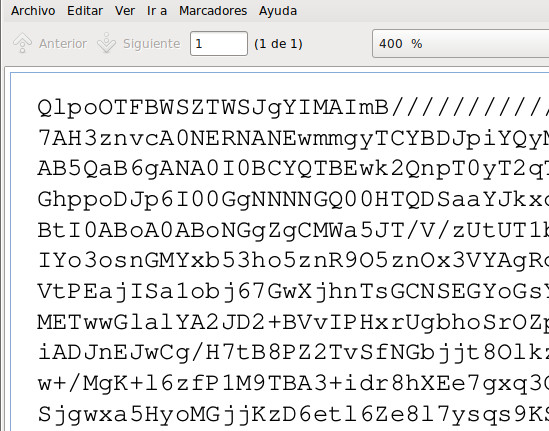
Para escribir el archivo en papel pensé en codificarlo en Base64. Este sistema codifica los datos binarios como caracteres de texto y es usado para incrustar datos binarios en sistemas de texto. Cada carácter puede tener 64 valores distintos: A-Z, a-z, 0-9 y otros dos caracteres que suelen ser "+" y "/". Esos 64 valores permiten codificar 6 bits con cada carácter (26 = 64). En Linux se puede utilizar el comando base64 para codificar los archivos. Con el parámetro -w se indica el número de caracteres por línea.
Con el objetivo de aumentar el número de bytes que se pueden codificar con un número determinado de caracteres se puede comprimir primero el archivo con Bzip2 u otro sistema de compresión. Por último es necesario formatear el texto con un tipo de letra y tamaño determinados. Para ello usé el programa enscript, que crea un documento PostScript con tamaño A4 por defecto. Con el parámetro -f se puede indicar la fuente y el tamaño. Con el parámetro --margins el tamaño de los márgenes, que podemos poner a 0 para escribir más caracteres en el papel. Usando la fuente Courier y tamaño 5 pude escribir 194 caracteres por línea. 194 caracteres/línea x 6 bits = 1164 bits/línea = 145,5 bytes/línea.
El archivo PostScript se puede convertir a PDF con el comando ps2pdf, incluido en el paquete ghostscript, para verlo en programas que no puedan leer archivos PostScript pero si archivos PDF. La salida de un programa se puede pasar como entrada al siguiente programa utilizando tuberías y nos queda la siguiente cadena de comandos:
# bzip2 -c archivo | base64 -w 194 | enscript -B -f Courier5 --margins=0:0:0:0 -p - | ps2pdf - archivo.pdf
Los archivos PostScript o PDF se pueden ver e imprimir con un visor de documentos como Atril. Luego podremos escanear el documento impreso con cualquier aplicación que pueda manejar el escáner. Es conveniente imprimir y escanear a la máxima calidad posible. Aún así la imagen escaneada tendrá imperfecciones producidas al imprimir y al escanear. Además al ser las letras muy pequeñas, de aproximadamente un milímetro, las imperfecciones son más importantes

Una vez escaneada la imagen hay que realizar el paso mas complicado, leer los caracteres. Para ello utilicé Tesseract, un software de OCR (Optical Character Recognition) (Reconocimiento Óptico de Caracteres). El resultado no fue nada bueno al ser las letras muy pequeñas, con muchas imperfecciones y Tesseract estar más preparado para detectar palabras que caracteres sueltos. Quizás entrenado a Tesseract para las características especiales de la imagen se podría mejorar el resultado pero quería que el sistema de reconocimiento de caracteres fuera algo sencillo.
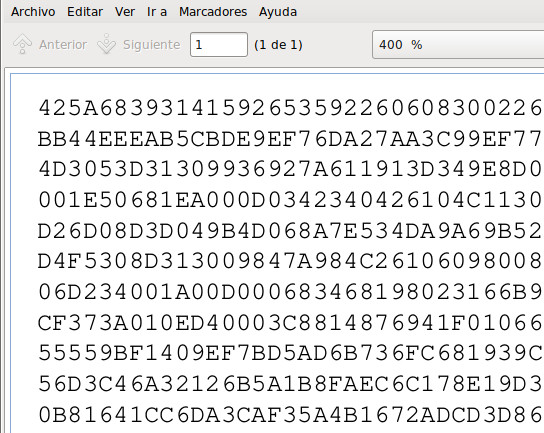
Para simplificar el reconocimiento de caracteres abandoné la idea de codificar los archivos en Base64 y pasé a codificarlos en hexadecimal. De esta forma solo es necesario distinguir 16 caracteres: 0-9 y A-F. Estos 16 valores permiten codificar 4 bits (24 = 16), por lo que para cada byte se utilizan 2 caracteres. Al poder codificar 2 bits/carácter menos que Base64 es necesario utilizar más caracteres para los mismos datos y a igual tamaño de carácter se podrá grabar menos información en el papel.
La codificación la realicé con el comando xxd. Con el parámetro -p imprime todos los caracteres seguidos y con el parámetro -c se indica el número de bytes (conjunto de 2 caracteres) por línea. Seguí usando la misma fuente y tamaño que con Base64, por lo que el número de caracteres por línea es el mismo. Con el parámetro -c le indico al programa que imprima 97 bytes por línea, 97 bytes x 2 caracteres = 194 caracteres.
# bzip2 -c archivo | xxd -u -p -c 97 | enscript -B -f Courier5 --margins=0:0:0:0 -p - | ps2pdf - archivo.pdf
El reconocimiento de caracteres con Tesseract mejoró bastante pero seguía habiendo muchos errores como confusión entre caracteres parecidos. Así que empecé a pensar en la forma de hacer un programa que fuera capaz de distinguir entre los 16 caracteres del sistema hexadecimal, pero el problema es complejo y es agravado por las imperfecciones de la imagen escaneada.

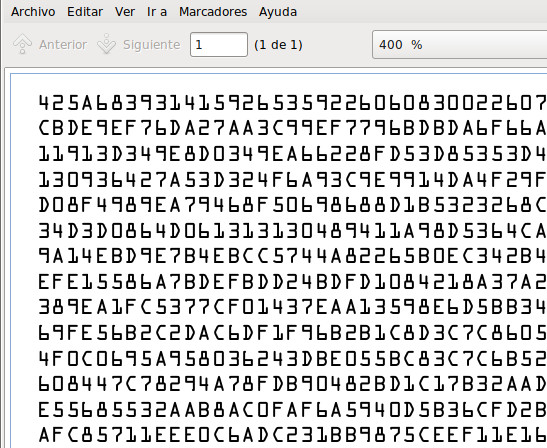
Para simplificar aún más la diferenciación de caracteres utilice la fuente OCR-A, creada en 1968 para facilitar el reconocimiento de caracteres. En esta fuente los caracteres son muy distintos entre si para poder diferenciarlos fácilmente. Por ejemplo el "8" es de menor anchura en la parte superior para diferenciarlo de la "B". Esto tiene la desventaja de que la forma de algunos caracteres es difícil de leer por humanos.
En Debian se puede instalar la fuente con el paquete fonts-ocr-a. También hay que instalar el paquete texlive-binaries, que contiene el programa ttf2afm, necesario para crear en el directorio de fuentes de enscript un archivo AFM (Adobe Font Metrics). Por último hay que añadir la fuente a la lista de fuentes de enscript en el archivo font.map.
# apt-get install fonts-ocr-a texlive-binaries # ttf2afm /usr/share/fonts/truetype/ocr-a/OCRA.ttf -o /usr/share/enscript/afm/OCRA.afm # vi /usr/share/enscript/afm/font.map OCRA OCRA
Al ser un tipo de letra distinto es necesario ajustar el tamaño de la fuente y el número de caracteres por línea. Con el tamaño 4 se pueden escribir 102 bytes/línea = 204 caracteres/línea.
# bzip2 -c archivo | xxd -u -p -c 102 | enscript -B -f OCRA4 --margins=0:0:0:0 -p - | ps2pdf - archivo.pdf
El reconocimiento con Tesseract empeoró pero pude hacer un programa que distinguía los caracteres la mayoría de las veces. Haciendo más sofisticado este programa quizás se pudiera llegar a un 100% de acierto, pero como dije antes buscaba un sistema sencillo.

Después de estos intentos llegué a la conclusión de que el reconocimiento de caracteres alfanuméricos es demasiado complicado y propenso a errores, sobre todo con caracteres tan pequeños y con muchas imperfecciones causadas por la impresión y el escaneo. Entonces pensé en una forma de escribir los archivos bit a bit en el papel. Para seguir utilizando los mismos programas opté por crear una fuente especialmente diseñado para representar los 4 bits del sistema hexadecimal.
Usando el programa FontForge creé una fuente con caracteres cuadrados que se dividen a su vez en cuatro cuadrados. Cada cuadrado representa un bit con valor cero cuando está en blanco y valor 1 cuando está en negro. El carácter "0" es un punto para diferenciarlo de un espacio en blanco. Todos los caracteres tienen las mismas dimensiones. Con esta fuente solo es necesario hacer un programa que lea los cuatro cuadrados e imprima los caracteres hexadecimales.
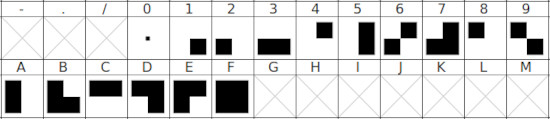
Al programa le he llamado HexImage y a la fuente FourBits porque sirve para codificar 4 bits. FontForge permite guardar el proyecto de fuente en un archivo SFD (Spline Font Database). Para usar la fuente con enscript es necesario exportarla a formato TrueType u OpenType y copiar el archivo al directorio de fuentes del sistema. En Debian se haría de la siguiente forma:
# mkdir /usr/share/fonts/truetype/fourbits # cp FourBits.ttf /usr/share/fonts/truetype/fourbits # mkdir /usr/share/fonts/opentype/fourbits # cp FourBits.otf /usr/share/fonts/opentype/fourbits
Al exportar la fuente a TrueType u OpenType también se crea un archivo AFM (Adobe Font Metrics) si está marcado en las opciones de exportación. Este archivo se debe copiar al directorio de fuentes de enscript y añadirlo a su lista de fuentes.
# cp FourBits.afm /usr/share/enscript/afm # vi /usr/share/enscript/afm/font.map FourBits FourBits
Después de instalar la fuente debemos ajustar el tamaño de fuente y número de caracteres por línea. Con el tamaño 4 se pueden imprimir 73 bytes/línea = 146 caracteres/línea.
# bzip2 -c archivo | xxd -u -p -c 73 | enscript -B -f FourBits4 --margins=0:0:0:0 -p - | ps2pdf - archivo.pdf
La cadena de comandos definitiva la podemos escribir en un script con nombre file2pdf.sh y sustituir los nombres de los archivos por variables para poder usar el script con diferentes archivos.
#! /bin/bash bzip2 -c $1 | xxd -u -p -c 73 | enscript -B -f FourBits4 --margins=0:0:0:0 -p - | ps2pdf - $2
# file2pdf.sh archivo archivo.pdf
Mientras desarrollaba el programa para leer los caracteres de la fuente me di cuenta de que aunque había tenido mucho cuidado de colocar bien el papel en la impresora y el escáner, la imagen estaba girada 0,06 grados. Utilizando el programa GIMP corregí ese giro para facilitar la lectura de las líneas de caracteres al poder seguir una línea horizontal sin tener que subir o bajar.
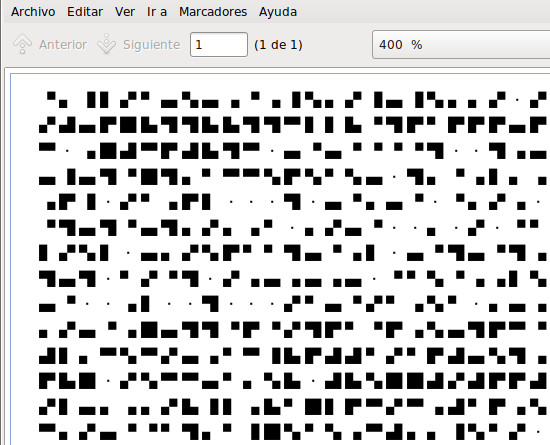

El programa se puede descargar en un archivo JAR ejecutable y tiene un archivo de configuración con una serie de parámetros que le ayudan a localizar los caracteres en la imagen:
- xStart e yStart: Coordenadas de comienzo del primer carácter.
- xIncrement: Puntos horizontales que debe avanzar el programa para llegar al siguiente carácter.
- yIncrement: Puntos verticales que debe avanzar el programa para llegar a la siguiente línea.
- characterWidth y characterHeight: Anchura y altura de la imagen a tomar de los caracteres.
- lineCharacters: Número de caracteres por línea.
- bitPixels: Mínimo número de puntos en negro para considerar que el cuadrado está en negro y representa un 1.
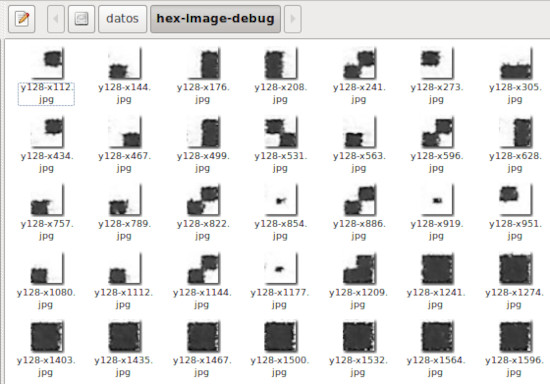
- debug: Activar la escritura de los caracteres analizados a un directorio para ser examinados.
- debugDirectory: Directorio donde escribir los caracteres.
El programa comienza en las coordenadas del primer carácter y toma una imagen del carácter con la anchura y altura indicadas. A continuación cuenta los puntos negros de los cuatro cuadrados que componen el carácter. Cuando termina de analizar un carácter avanza los puntos indicados para llegar al siguiente carácter. La anchura de la imagen y puntos horizontales a avanzar son distintos porque la anchura de la imagen del carácter debe ser un número entero, en cambio los puntos a avanzar es un número en coma flotante porque la media de espacio entre caracteres de la imagen escaneada no es un número exacto de puntos.
Cuando el programa ha analizado el número de caracteres por línea indicado, vuelve a la coordenada horizontal de inicio del primer carácter y avanza verticalmente los puntos indicados para llegar a la siguiente línea. Este número de puntos también es distinto que la altura de la imagen de los caracteres y en coma flotante por la misma razón que los puntos horizontales y porque entre líneas hay un espacio. El programa finaliza cuando toma una imagen de carácter y no encuentra ningún punto, lo que significa que ha encontrado un espacio en blanco y ya no hay más caracteres.
Debido a las imperfecciones de impresión y escaneo, en las imágenes de caracteres que toma el programa los caracteres no están perfectamente centrados ni horizontal ni verticalmente. Esto hace que al contar los puntos de uno de los cuatro cuadrados no se cuenten algunos puntos de ese cuadrado o se cuenten puntos de algún cuadrado adyacente. Además las imperfecciones también hacen que caracteres iguales tengan diferente número de puntos. Aún con estos problemas es posible detectar si un cuadrado está en negro si el número de puntos detectados supera el mínimo número indicado en la configuración.
xStart=112 yStart=128 characterWidth=30 characterHeight=30 xIncrement=32.28 yIncrement=40.48 lineCharacters=146 bitPixels=140 debug=false debugDirectory=hex-image-debug/
El programa después de analizar un carácter y detectar los cuadrados que están en blanco o negro utiliza los operadores a nivel de bits "<<" y "|" para convertir esta información a un grupo de cuatro bits con un valor entre 0 y 15 que indica el carácter hexadecimal a imprimir.
char[] characters = {'0', '1', '2', '3', '4', '5', '6', '7', '8', '9',
'A', 'B', 'C', 'D', 'E', 'F'};
...
int pixels[] = new int[4];
int bits[] = new int[4];
...
for (int b = 0; b < 4 ; b++) {
bits[b] = pixels[b] > bitPixels ? 1 : 0;
}
int character = bits[0] << 3 | bits[1] << 2 | bits[2] << 1 | bits[3];
System.out.print(characters[character]);
La salida de caracteres hexadecimales se le puede pasar al programa xxd. Con el parámetro -r se le ordena que en lugar de codificar un archivo en caracteres hexadecimales haga la operación inversa, leer los caracteres hexadecimales y codificarlo en binario. Para recuperar el archivo original el último paso necesario es descomprimirlo con bunzip2.
# java -jar HexImage.jar imagen-escaneada.jpeg hex-image.properties | xxd -r -p | bunzip2 > archivo-recuperado
Para comprobar que el archivo se ha recuperado correctamente se puede comparar con el archivo original utilizando el comando diff.
# diff archivo-recuperado archivo-original
Dependiendo del tamaño de fuente, el número de caracteres por línea y las características de la impresora y escáner utilizados será necesario calibrar los parámetros de configuración para una correcta lectura. Para ver si el programa está leyendo bien los caracteres podemos activar la escritura de las imágenes de los caracteres a un directorio asignando el valor "true" al parámetro de configuración debug. Además el parámetro debugDirectory debe apuntar a un directorio existente donde escribir las imágenes. En el nombre de los archivos de imagen se indican las coordenadas de inicio de la imagen. La coordenada "y" aparece primero para que las imágenes se ordenen por filas.
Esto es todo lo que necesitamos para grabar en una hoja de papel un archivo que al comprimirlo con Bzip2 ocupe unos 12 KiB. Y es posible que se puedan grabar archivos mayores utilizando un tamaño de fuente menor, sobre todo usando mejores impresoras y escáneres. Otra posibilidad sería crear una fuente de 6 cuadrados, que representen 6 bits, para poder codificar Base64. Usando varios colores también se podrían codificar más caracteres con los mismos cuadrados. Con 4 cuadrados cada color añadido permite codificar 16 caracteres más.
Haciendo un sistema que en lugar de usar una fuente pudiera imprimir los 4 cuadrados por separado y con distinto color el número de combinaciones posible sería colores4. Con 4 colores, incluidos el blanco y negro, puede haber 44 = 256 combinaciones, lo que equivale a 1 byte/8 bits por carácter (28 = 256).
No hay comentarios:
Publicar un comentario